LRM: Large Reconstruction Model
for Single Image to 3D
Interactable Meshes
Toy Giraffe
Tea Cup
Teddy Bear
Wood Peafowl
Cherry
Toy Flower
Abstract
We propose the first Large Reconstruction
Model (LRM) that predicts the 3D model
of an object from a single input image within just 5 seconds.
In contrast to many previous methods that are trained on small-scale datasets
such as ShapeNet in a category-specific fashion, LRM adopts a highly scalable
transformer-based architecture with 500 million learnable parameters to directly
predict a neural radiance field (NeRF) from the input image. We train our model
in an end-to-end manner on massive multi-view data containing around 1 million
objects, including both synthetic renderings from Objaverse and real captures
from MVImgNet. This combination of a high-capacity model and large-scale training
data empowers our model to be highly generalizable and produce high-quality 3D
reconstructions from various testing inputs including real-world in-the-wild
captures and images from generative models.
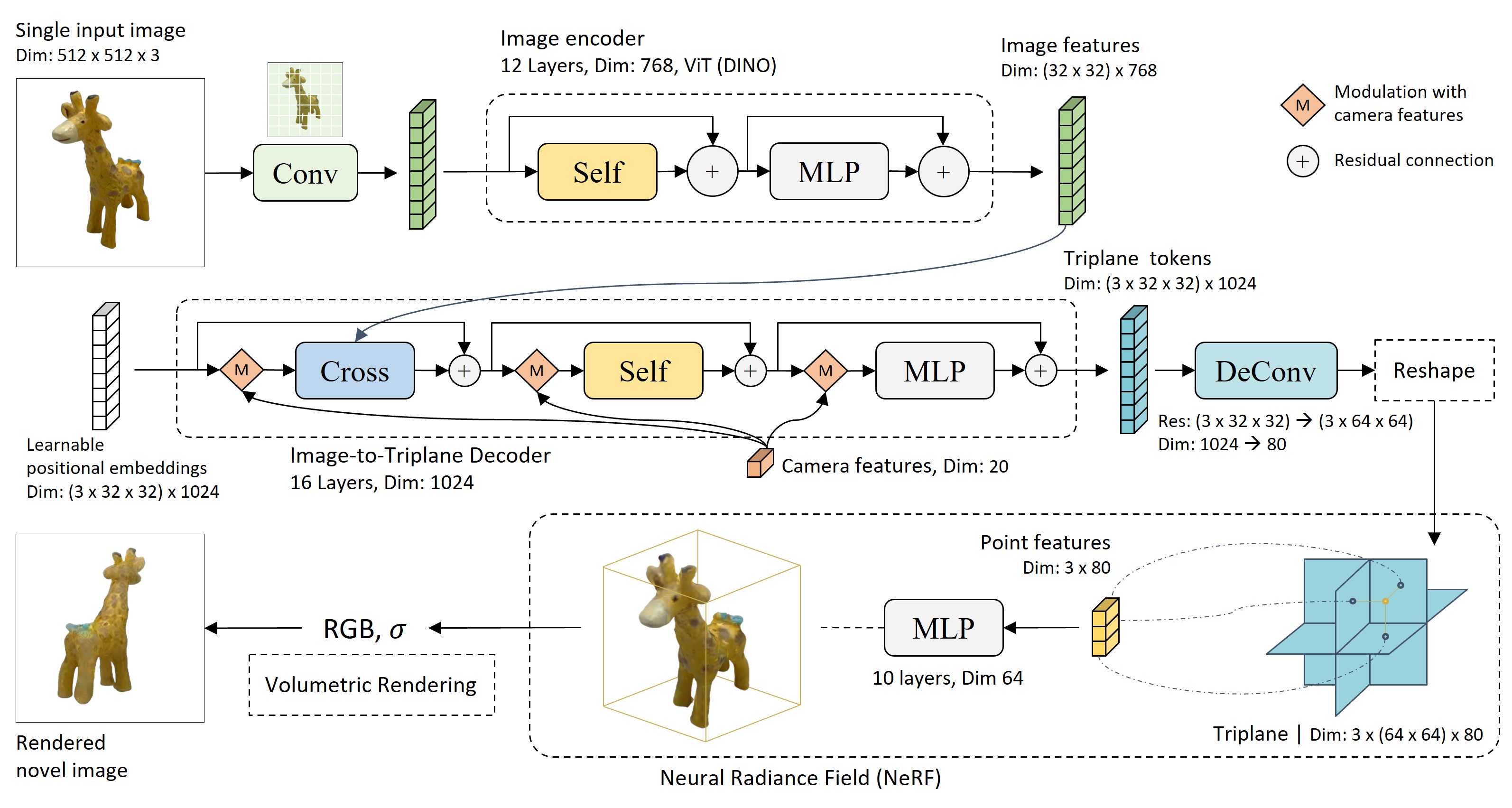
Figure 1. The overall architecture of LRM, a fully-differentiable transformer-based encoedr-decoder framework for single-image to NeRF reconstruction. LRM applies a pre-trained vision model (DINO) to encode the input image, where the image features are projected to a 3D triplane representation by a large transformer decoder via cross-attention, followed by a multi-layer perceptron to predict the point color and density for volumetric rendering. The entire network is trained end-to-end on around a million of 3D data by simply minimizing the difference between the rendered images and ground truth images at novel views.